Machine Learning Cheat Sheet

Hast du dich jemals von der schieren Menge an Informationen, Algorithmen und Konzepten im Bereich des maschinellen Lernens (ML) überwältigt gefühlt? Keine Sorge, du bist nicht allein! Dieses Cheat Sheet ist dein Leitfaden, um die wichtigsten Grundlagen des Machine Learnings schnell zu erfassen und anzuwenden. Egal, ob du ein Anfänger bist, der gerade erst anfängt, oder ein erfahrener Praktiker, der eine schnelle Auffrischung benötigt, dieses Dokument soll dir helfen, dich in der komplexen Welt des ML zurechtzufinden.
Zielgruppe: Dieses Cheat Sheet richtet sich an:
- Studierende, die Machine Learning lernen
- Datenwissenschaftler, die eine schnelle Referenz benötigen
- Softwareentwickler, die ML in ihre Projekte integrieren möchten
- Projektmanager, die ein besseres Verständnis von ML-Projekten benötigen
Grundlegende Konzepte
Bevor wir uns in die Details stürzen, ist es wichtig, einige grundlegende Konzepte zu verstehen:
Must Read
- Daten: Die Grundlage des maschinellen Lernens. ML-Modelle lernen aus Daten, um Vorhersagen zu treffen oder Entscheidungen zu treffen.
- Merkmale (Features): Die einzelnen Attribute oder Spalten in deinen Daten, die zur Vorhersage verwendet werden.
- Zielvariable (Target Variable): Die Variable, die du vorhersagen möchtest (auch bekannt als Label oder Ergebnis).
- Modell: Eine mathematische Repräsentation des Zusammenhangs zwischen den Merkmalen und der Zielvariablen.
- Training: Der Prozess, bei dem das Modell anhand der Daten lernt.
- Validierung: Der Prozess, bei dem die Leistung des Modells anhand eines separaten Datensatzes bewertet wird, um sicherzustellen, dass es generalisiert.
- Testen: Der abschließende Prozess, bei dem die Leistung des Modells anhand eines komplett neuen Datensatzes bewertet wird, um seine Leistungsfähigkeit in realen Szenarien zu beurteilen.
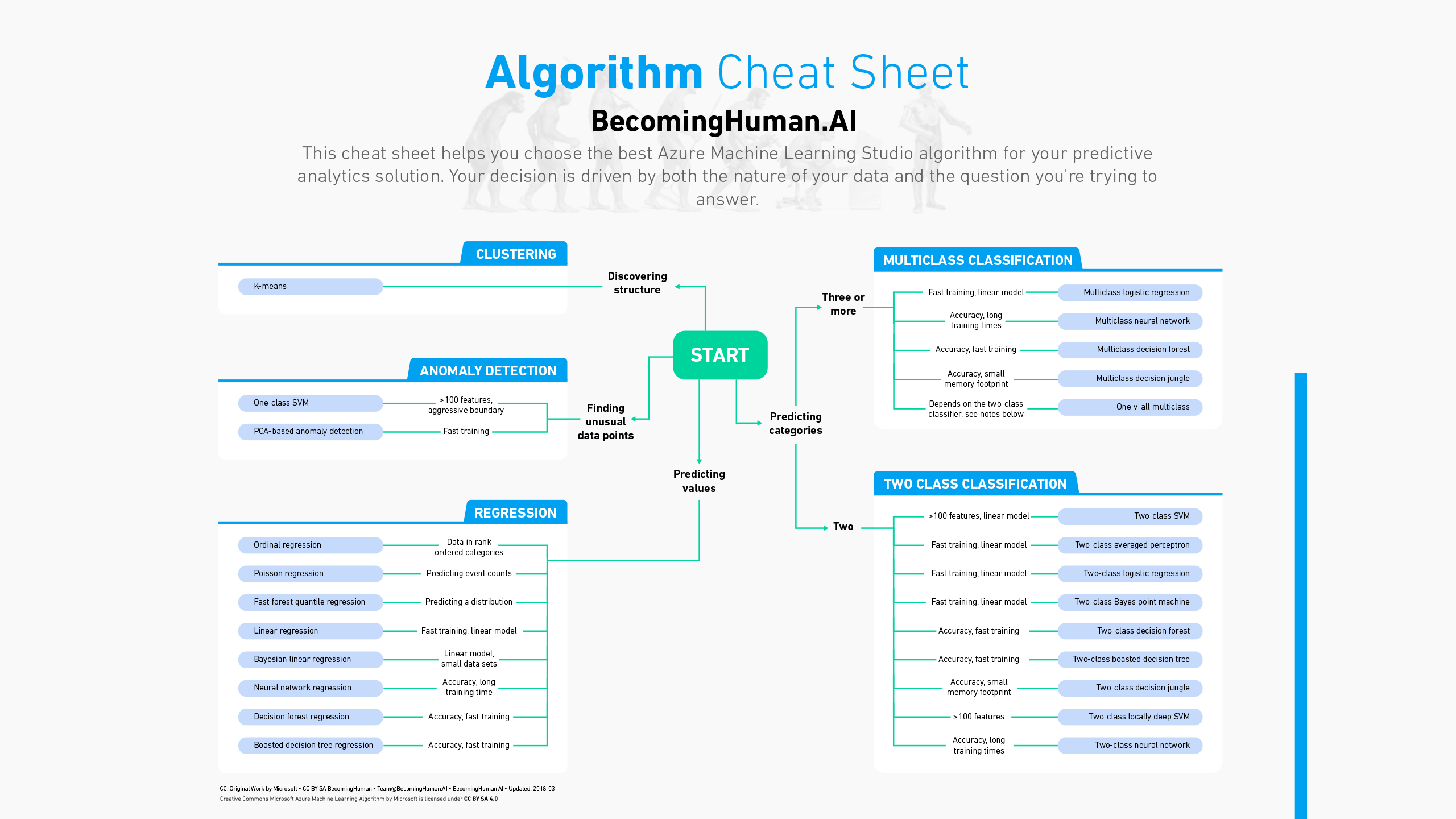
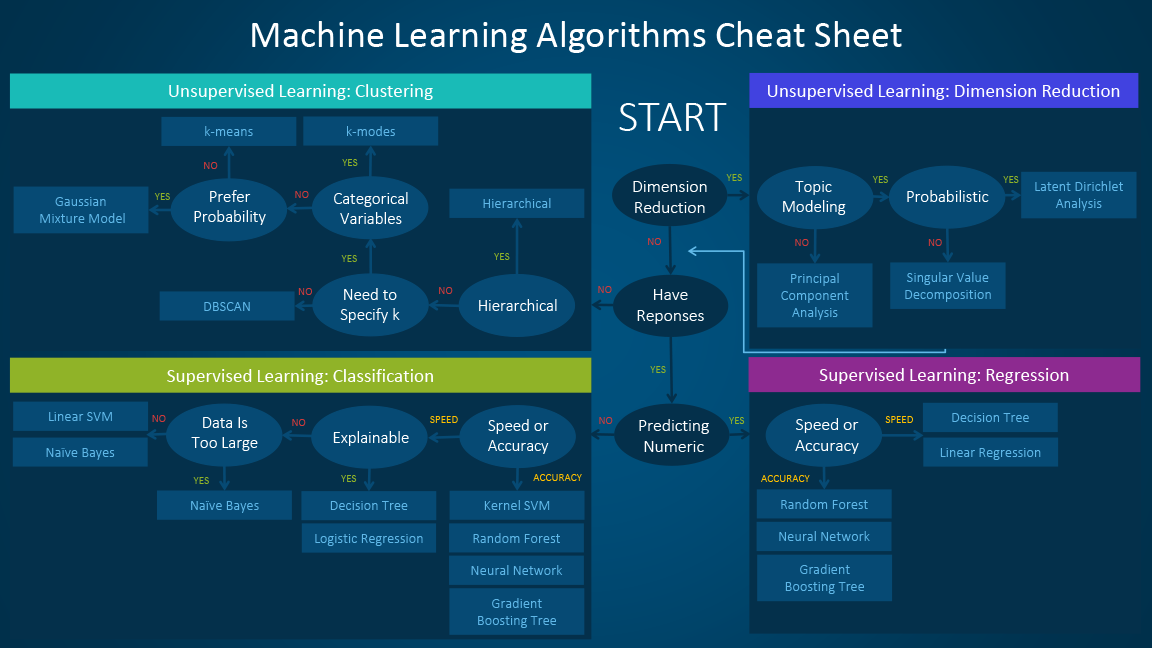
Arten von Machine Learning
Machine Learning lässt sich grob in drei Haupttypen einteilen:
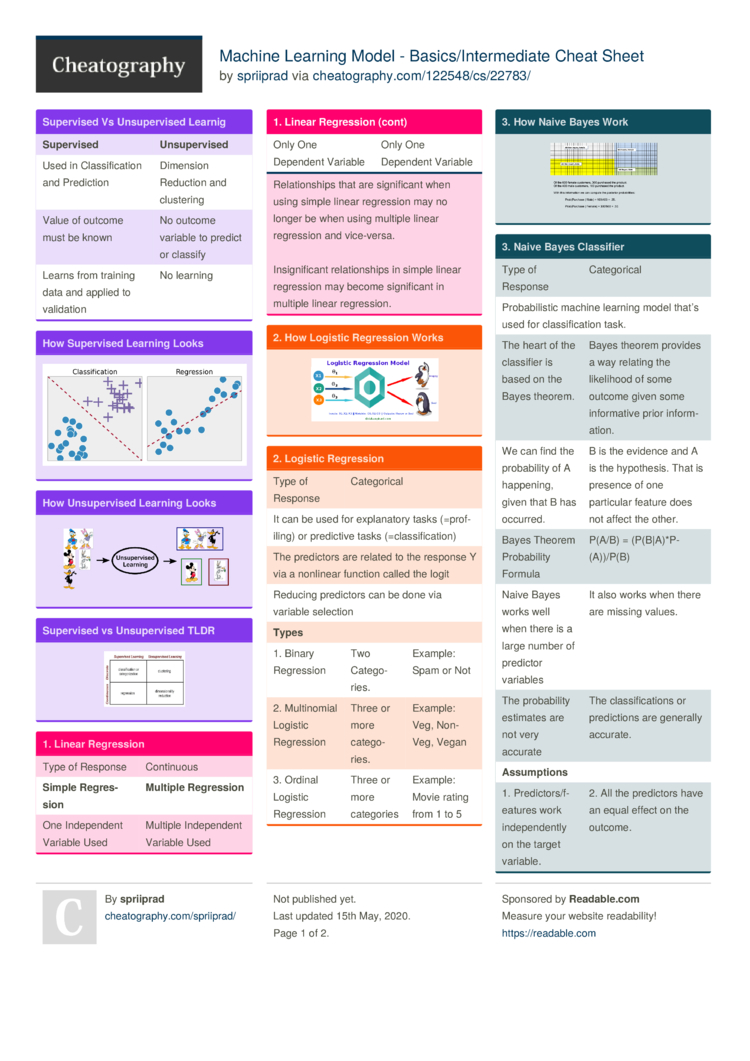
Supervised Learning (Überwachtes Lernen)
Beim überwachten Lernen werden Modelle anhand von gelabelten Daten trainiert. Das bedeutet, dass du sowohl die Eingabemerkmale als auch die entsprechende Zielvariable kennst.

Beispiele:
- Klassifizierung: Vorhersage einer Kategorie (z.B. Spam oder Nicht-Spam). Algorithmen wie Logistic Regression, Support Vector Machines (SVMs) und Decision Trees werden hier häufig verwendet.
- Regression: Vorhersage eines kontinuierlichen Wertes (z.B. Preis eines Hauses). Lineare Regression, Polynomiale Regression und Random Forests sind beliebte Algorithmen.
Unsupervised Learning (Unüberwachtes Lernen)
Beim unüberwachten Lernen werden Modelle anhand von ungelabelten Daten trainiert. Das Ziel ist, Muster, Strukturen oder Beziehungen in den Daten zu finden.
Beispiele:
- Clustering: Gruppierung ähnlicher Datenpunkte (z.B. Kundensegmentierung). K-Means Clustering und Hierarchisches Clustering sind gängige Techniken.
- Dimensionsreduktion: Reduzierung der Anzahl der Merkmale unter Beibehaltung der wichtigsten Informationen (z.B. Principal Component Analysis (PCA)).
- Assoziationsanalyse: Entdeckung von Beziehungen zwischen Variablen (z.B. Warenkorbanalyse).
Reinforcement Learning (Bestärkendes Lernen)
Beim Reinforcement Learning lernt ein Agent, in einer Umgebung zu agieren, um eine Belohnung zu maximieren. Der Agent lernt durch Versuch und Irrtum.
Beispiele:

- Spiele spielen: Agenten lernen, Spiele wie Go oder Schach zu spielen.
- Robotik: Steuerung von Robotern, um Aufgaben auszuführen.
- Ressourcenmanagement: Optimierung der Ressourcenzuteilung.
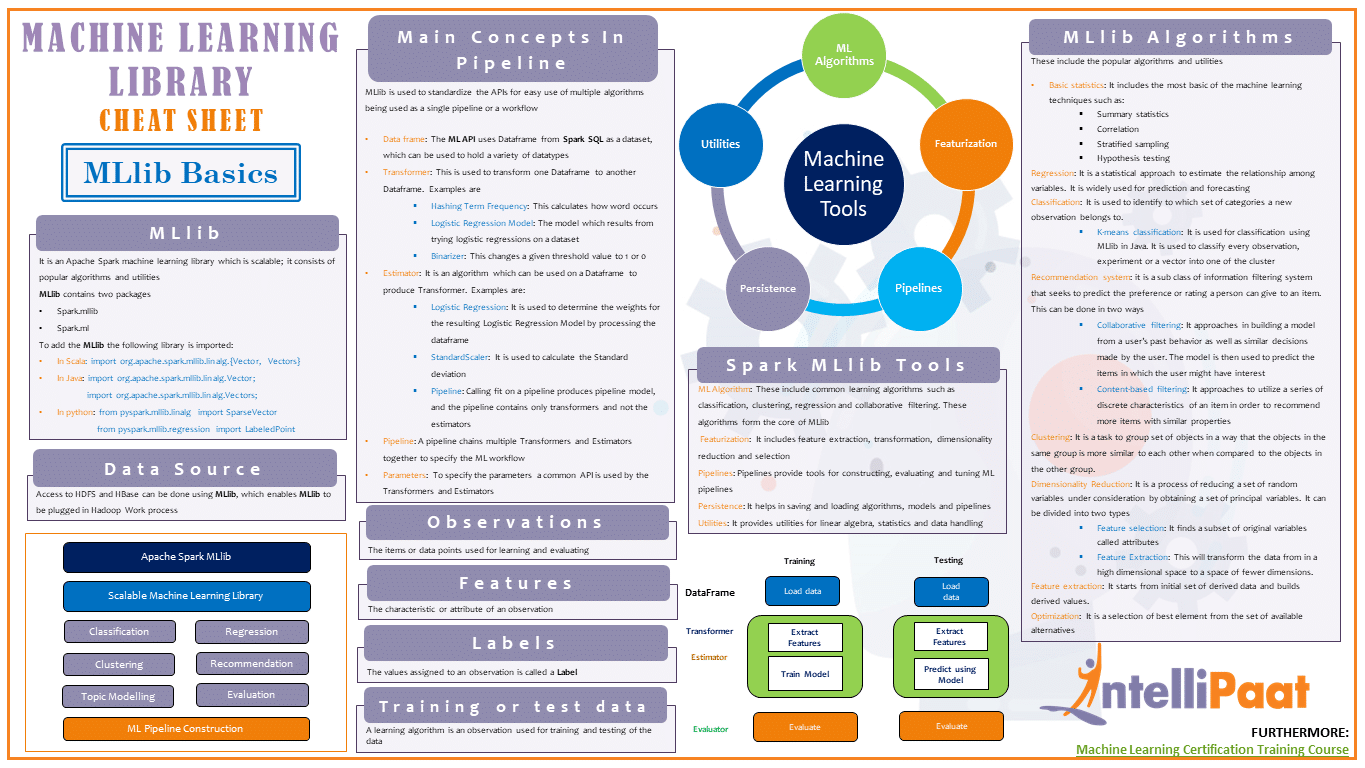
Wichtige Algorithmen
Hier ist eine Übersicht über einige der am häufigsten verwendeten Machine Learning Algorithmen:
- Lineare Regression: Ein einfacher, aber leistungsstarker Algorithmus zur Vorhersage kontinuierlicher Werte.
- Logistische Regression: Ein Algorithmus zur Vorhersage von Kategorien.
- Support Vector Machines (SVM): Ein Algorithmus, der effektiv für Klassifizierung und Regression eingesetzt werden kann.
- Decision Trees: Ein Algorithmus, der Entscheidungen anhand einer Baumstruktur trifft.
- Random Forest: Eine Sammlung von Decision Trees, die zusammenarbeiten, um genauere Vorhersagen zu treffen.
- K-Means Clustering: Ein Algorithmus zur Gruppierung ähnlicher Datenpunkte.
- Principal Component Analysis (PCA): Eine Technik zur Dimensionsreduktion.
- Neuronale Netze: Komplexe Modelle, die in der Lage sind, hochkomplexe Muster zu lernen.
Modellbewertung
Es ist wichtig, die Leistung deines Modells zu bewerten, um sicherzustellen, dass es gut generalisiert. Hier sind einige gängige Metriken:

- Genauigkeit (Accuracy): Der Anteil der korrekt vorhergesagten Instanzen.
- Präzision (Precision): Der Anteil der korrekt identifizierten positiven Instanzen unter allen als positiv vorhergesagten Instanzen.
- Rückruf (Recall): Der Anteil der korrekt identifizierten positiven Instanzen unter allen tatsächlichen positiven Instanzen.
- F1-Score: Der harmonische Mittelwert von Präzision und Rückruf.
- RMSE (Root Mean Squared Error): Ein Maß für die Differenz zwischen den vorhergesagten und den tatsächlichen Werten (wird für Regression verwendet).
- R-Quadrat (R²): Ein Maß für die erklärte Varianz (wird für Regression verwendet).
Wichtige Schritte im Machine-Learning-Workflow
Ein typischer Machine-Learning-Workflow umfasst folgende Schritte:
- Datenerhebung: Sammle die relevanten Daten für dein Problem.
- Datenvorbereitung: Bereinige, transformiere und bereite die Daten für das Training vor. Dies umfasst den Umgang mit fehlenden Werten, die Skalierung von Merkmalen und die Kodierung kategorialer Variablen.
- Merkmalsauswahl: Wähle die relevantesten Merkmale für dein Modell aus.
- Modellauswahl: Wähle den am besten geeigneten Algorithmus für dein Problem.
- Modelltraining: Trainiere das Modell anhand der Trainingsdaten.
- Modellvalidierung: Bewerte die Leistung des Modells anhand der Validierungsdaten.
- Modelloptimierung: Passe die Modellparameter an, um die Leistung zu verbessern.
- Modelltest: Bewerte die endgültige Leistung des Modells anhand der Testdaten.
- Modellbereitstellung: Stelle das Modell bereit, um Vorhersagen zu treffen.
Tipps und Tricks
Hier sind einige zusätzliche Tipps, um deinen Machine-Learning-Workflow zu verbessern:
- Verstehe deine Daten: Verbringe Zeit damit, deine Daten zu untersuchen, um Muster und Ausreißer zu identifizieren.
- Verwende die richtige Metrik: Wähle die Metrik, die am besten zu deinem Problem passt.
- Achte auf Overfitting: Overfitting tritt auf, wenn das Modell zu gut an die Trainingsdaten angepasst ist und nicht gut generalisiert.
Regulierungstechniken wie L1- und L2-Regularisierung können helfen, Overfitting zu verhindern.
- Verwende Cross-Validation: Cross-Validation hilft dabei, die Leistung des Modells zuverlässiger zu schätzen.
- Experimentiere: Scheue dich nicht, verschiedene Algorithmen und Techniken auszuprobieren.
- Bleibe auf dem Laufenden: Der Bereich des Machine Learnings entwickelt sich ständig weiter. Bleibe auf dem Laufenden über die neuesten Fortschritte und Techniken.
Dieses Cheat Sheet soll dir einen schnellen Überblick über die wichtigsten Konzepte und Algorithmen im Machine Learning geben. Nutze es als Ausgangspunkt für deine Reise in die Welt des maschinellen Lernens und erweitere dein Wissen kontinuierlich. Viel Erfolg!